The IonQ Quantum Cloud has one of the best—maybe the best—optimizing compilers in quantum computing. This allows users to focus on the details of their algorithms instead of the details of our quantum system. You can submit quantum circuits using a large, diverse set of quantum gates that allows for maximum flexibility in how to define your problem, and our compilation and optimization stack ensures that your circuit runs on our QPUs in the most compact, streamlined, hardware-optimized form possible.
This flexibility in circuit definition also allows for high portability of algorithm code. We don’t restrict you to hardware-native basis gates, so you’re free to define your circuit in standard QIS gates (including controlled and multi-controlled variants of these) and then simply submit to IonQ hardware as-is. No changes necessary!
While this is ideal for many applications, the hardware-native basis gateset allows for more customizability, flexibility, and what-you-submit-is-what-you-get control. Being as “close to the metal” as possible allows for control over each individual gate and qubit, unlocking avenues of exploration that are impossible with a compiler between you and the qubits. Currently, submitting circuits defined in native gates is the only way to bypass the compiler and optimizer.
Read on to get started with our hardware-native gate specification, learn how it works, and how to run an example circuit using this powerful new ability.
When to use native gates
Native gates are not the right solution for every problem. As the warning above states, the native gate specification is an advanced-level feature. If your goal is simply to run a quantum circuit for evaluation or algorithm investigation purposes, using native gates will often result in lower-quality output than simply using the abstract gate interface. The native gate interface is the simplest, most direct way to run a circuit on IonQ hardware: we run exactly the gates you submitted, as submitted, and we return the results. That’s it.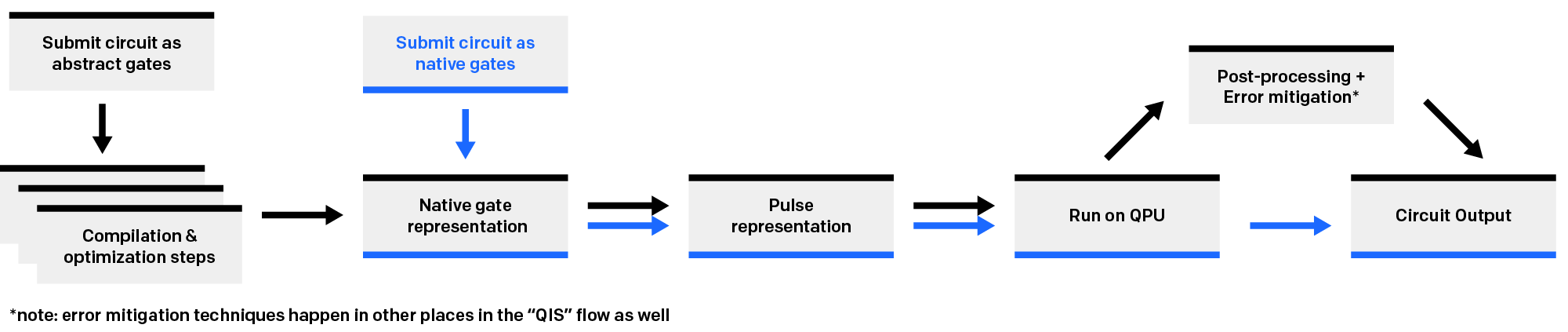
Introducing the native gates
The native gateset is the set of quantum gates that are physically executed on IonQ hardware by addressing ions with resonant lasers via stimulated Raman transitions. The physical implementation of Raman gates differs between Forte and Aria, which means they support a slightly different set of native gates:
We currently expose two single-qubit gates and one two-qubit entangling gate for each QPU. Other native gates may be provided in the future.
All gate parameters are measured in turns rather than in radians: a value of 1 turn corresponds to 2π radians. We track the phase at the pulse level as units of turns—or, more accurately, as units of how long a turn takes—so, we expose the controls in the same way to you. This reduces floating point conversion error between what you submit and what runs.
Single-qubit gates
The “textbook” way to think about single-qubit gates is as rotations along different axes on the Bloch sphere, but another way to think about them is as rotations along a fixed axis while rotating the Bloch sphere itself. Because, in physical reality, the Bloch sphere itself is rotating—that is, the phase is advancing in time—changing the orientation of the Bloch sphere is virtually noiseless on hardware. As such, we manipulate qubit states in this “noiseless” phase space whenever possible.GPi
The GPi (“Gate Pi”) gate can be considered a π or bit-flip rotation with an embedded phase. It always rotates π radians in the polar angle—hence the name—but can rotate on any longitudinal axis of the Bloch sphere. The axis of rotation is set by the parameter ϕ, which is measured in turns. At a ϕ of 0 turns the GPi gate is equivalent to an X gate, and at a ϕ of 0.25 turns (π/2 radians) it is equivalent to a Y gate, but it can also be mapped to any other azimuthal angle. In terms of standard quantum gates, a GPi gate can be decomposed as:GPi2
The GPi2 gate could be considered an RX(π/2)—or RY(π/2)—rotation with an embedded phase. It always rotates π/2 radians but can rotate on any longitudinal axis of the Bloch sphere. In practice, a GPi2 gate works similarly to a GPi gate but uses either a lower amplitude or shorter duration physical pulse (we do not expose this implementation detail). While it’s technically possible to set arbitrary rotation angles, using just π/2 rotations along with phase control is sufficient for universal quantum computation. As with the GPi gate, the axis of rotation is set by the parameter ϕ, defined in turns. At a ϕ of 0.5 turns (π radians) the GPi2 gate is equivalent to RX(π/2), and at a ϕ of 0.25 turns (π/2 radians) it is equivalent to RY(π/2), but it can also be mapped to any other azimuthal angle. Like the GPi gate, the GPi2 gate is physically implemented as a Rabi oscillation made with a two-photon Raman transition.Virtual Z
We do not expose or implement a “true” Z gate (sometimes also called a P, Phase Gate, or RZ gate), where we wait for the phase to advance in time. Instead, a Virtual RZ can be performed by simply advancing or retarding the phase of the following operation in the circuit. This process, called “phase propagation,” removes RZ gates by adding their angles to the phase parameters of subsequent gates. For example, to add RZ(θ)—an RZ with an arbitrary rotation θ—to a qubit where the subsequent operation is GPi(0.5), we can just add that rotation to the phases of the following gates:—RZ(θ)—GPi(0.5)—GPi2(0) = —GPi(θ + 0.5)—GPi2(θ + 0)
Entangling gates
For entangling gates, we offer different options for each QPU: the Mølmer-Sørensen gate on Aria-class systems, and the ZZ gate on our Forte-class systems.MS gates
Invented in 1999 by several groups simultaneously, the Mølmer-Sørensen gate along with single-qubit gates constitutes a universal gate set. By irradiating any two ions in the chain with a predesigned set of pulses, we can couple the ions’ internal states with the chain’s normal modes of motion to create entanglement. While it is possible to entangle many qubits simultaneously with the Mølmer-Sørensen interaction via global MS, or GMS, we only offer two-qubit MS gates at this time. Fully entangling MS The fully entangling MS gate is an XX gate—a simultaneous, entangling π/2 rotation on both qubits. Like our single-qubit gates, they nominally follow the X axis as they occur, but take two phase parameters that make e.g. YY or XY also possible. The first phase parameter ϕ0 refers to the first qubit’s phase (measured in turns) as it acts on the second one, the second parameter ϕ1 refers to the second qubit’s phase (measured in turns) as it acts on the first one. If both are set to zero, there is no advancing phase between the two qubits because the transition is driven on both qubits simultaneously, in-phase. That is, the relative phase between the two qubits remains the same during the operation unless a phase offset is provided. Note that while two distinct ϕ parameters are provided here (one for each qubit, effectively), they always act on the unitary together. This means that there are multiple ways to get to the same relative phase relationship between the two qubits for this gate; two parameters just makes the recommended approach of “Virtual Z” phase accounting on each qubit across the entire circuit a little neater. Partially entangling MS In addition to the fully entangling MS gate described above, we also support partially entangling MS gates, which are useful in some cases. To implement these gates, we add a third (optional) arbitrary angle θ: This parameter is also measured in turns, and can be any floating-point value between 0 (identity) and 0.25 (fully-entangling); in practice, the physical hardware is limited to around three decimal places of precision. Requesting an MS gate without this parameter will always run the fully entangling version. Partially entangling MS gates yield more compact circuits: to produce the same effect as one arbitrary-angle MS gate would require up to two fully-entangling MS gates plus four single-qubit rotations. This offers a potential reduction in gate depth that can indirectly improve performance by removing unnecessary gates in certain circuits. Additionally, small-angle MS gates are generally more performant: for smaller angles, these gates are implemented by lower-power laser pulses, and therefore experience lower light shift and other power-dependent errors. We do not currently have a detailed characterization of how much more performant these gates are on our current-generation systems, but in our (now-decommissioned) system described in this paper, we saw an improvement from ~97.5% to ~99.6% two qubit fidelity when comparing angles of π/2 and π/100, which is described in more detail here.ZZ gates
Our Forte systems use the ZZ gate, which is another option for creating entanglement between two qubits. Unlike the Mølmer-Sørensen gate, the ZZ gate only requires a single parameter, θ, to set the phase of the entanglement.Converting to native gates
You can write a quantum circuit using native gates directly, but you can also convert an abstract-gate circuit into native gates. To do this automatically, we support Qiskit’s transpiler. Here, we’ll walk through the general approach for manually translating circuits into native gates.General algorithm
To translate anything into native gates, the following general approach works well:- Decompose the gates used in the circuit so that each gate involves at most two qubits.
- Convert all easy-to-convert gates into RX, RY, RZ, and CNOT gates.
- Convert CNOT gates into XX gates using the decomposition described here and at the bottom of this section.
- For hard-to-convert gates, first calculate the matrix representation of the unitary, then use either KAK decomposition or the method introduced in this paper to implement the unitary using RX, RY, RZ and XX. Note that Cirq and Qiskit also have subroutines that can do this automatically, although potentially not optimally. See cirq.kak_decomposition and qiskit.synthesis.TwoQubitBasisDecomposer.
- Write RX, RY, RZ and XX into GPi, GPi2 and MS gates as documented above (making sure to convert all angles and phases from radians to turns).